Troubleshooting Javascript for SEO Part 1
Javascript Troubleshooting
With the rise of heavy Javascript powered frameworks came increased problems for SEOs. Javascript is seen as complicated because it’s not typically something an SEO would know unless they’ve done dev work, and because there are multiple frameworks out there. It’s also daunting because we’ve all either heard of or seen the horror stories firsthand that result in a site taking a heavy hit in rankings due to using a heavy Javascript framework.
However, analyzing Javascript heavy sites doesn’t need to be daunting. We’ll take you through the main way we test for issues in Part 1, and in Part 2 we’ll show you a few examples of what you might find.
Javascript Page Emulating
The first thing you need to learn how to do is emulate a page. This is a critical step in understanding what Google sees. You can do this in one of two ways:
- Create a new tab and edit the HTML to paste in the page you wish to emulate
- Use JSBin.com to view the page you wish to emulate.
Both of these options work, and typically I stick with JSbin.com, but sometimes you just need to use your own tabs (it’s easier to search for code in the DOM of a new tab compared to searching in JSBin).
Step 1: Grabbing the Code
Now in most cases you’ll want to emulate the code you receive from the URL Inspection Tool. You’ll be greeted with this view once you’ve inspected a URL and selected the Live Test option.
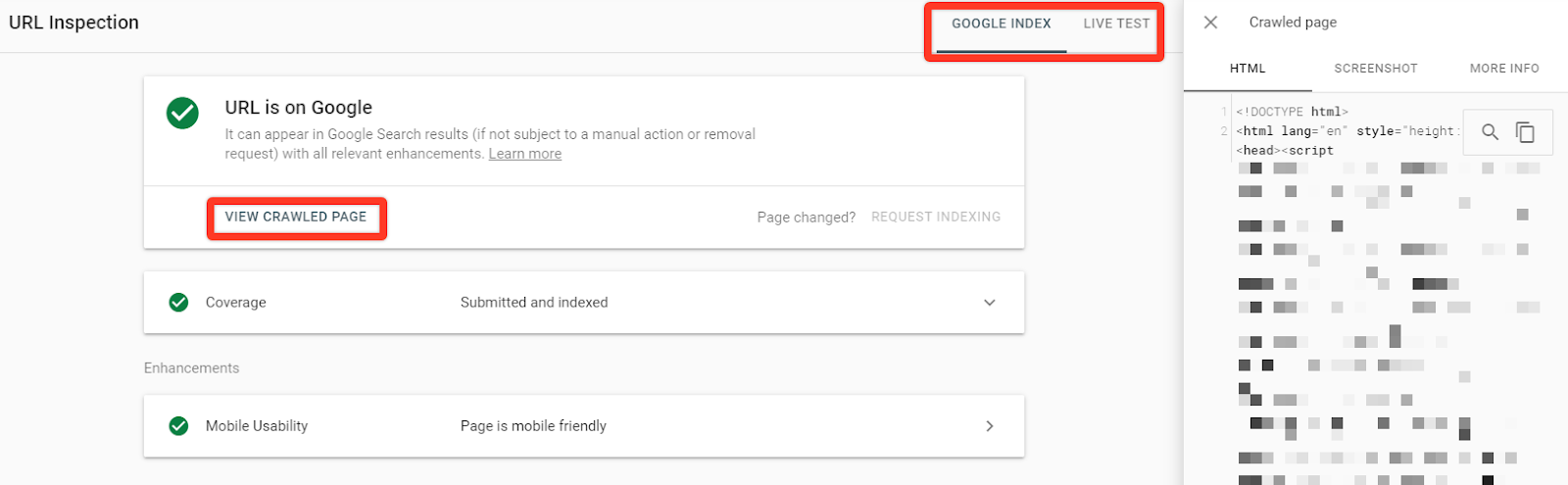
You’ll notice that after the live test is performed, you’ll have the option to switch between the Google Index version of the page, and the page you just tested. On both of these versions you’ll have the option to view the crawled page, which pulls out the sidebar showing you the HTML that was crawled, and a screenshot if you perform a live test.
The difference between the Google Index version and the Live Test version is that the Google Index version is what Google currently has indexed.
It’s important to keep in mind that this supersedes whatever is in the cache as well. The cache may contain the same information, but if it’s different, then whatever the Google Index Crawled HTML shows is what it is using.
If you don’t use prerender, you’ll at first be stuck with whatever HTML is present until Google renders your full content using the WRS (Web Rendering Service). At that point, you’ll see that Google has swapped out the old code for the new in the crawled HTML.
Note: This process doesn’t have a definitive timeline and can take a couple weeks at times.
The Live Test view on the other hand renders the page at the same time, showing you exactly what Google will eventually see once it has rendered the content (or immediately sees if you use prerendering services, Server-Side Rendering (SSR) or Dynamic Rendering).
If you don’t have access to a website’s GSC, you can use the rich results tester to do this as well. The only downside there is you don’t get to see what Google has indexed. If possible always use GSC and URL Inspection first, and the rich results tester second. Additionally, sometimes you can verify if prerendering is in play by swapping the user-agent to Googlebot, but that’s not always the case.
Step 2: Emulating the Code
Once you’ve inspected the page, copy the code that is displayed when you select View Crawled Page. There’s a little button you can click to copy all of the code, or just manually select all and copy it.
Note: You’ll notice many pages tend to look pretty bare. This results when a website is using relative URLs for JS/CSS and/or Images. You won’t load the files so you’ll see the site as if you had CSS disabled. You can use a code editor and add in the correct location if you wish.
Method One: New Tab
- Open up a new tab in your browser (we’re using Chrome for this demonstration)
- Open up your dev tools (CTRL + SHIFT + I, or right click → inspect element).
- Right click the <HTML> tag and select Edit as HTML
- Select the current code and replace with the copied code
- Click outside of the edit area to save your changes
- Visually review the site and search for any code you’re looking to verify Google has it in their crawl
Method Two: JSBin.com
- Head to https://jsbin.com/
- Select the default code and replace with the copied code
- Visually review the site and search for any code you’re looking to verify Google has it in their crawl
Where JSBin differs from just emulating in a normal tab is it’s easier to review responsive frameworks. This is still possible in the New Tab method, but it’s an additional step.
Here are a couple of videos to see this in action.
Emulating Javascript pages in a new tab
Emulating Javascript pages in JSBin.com
User-Agent Testing for Prerendered Pages
While emulating Javascript pages is the main way I troubleshoot issues to make sure prerender is working properly, there is a better way to ensure that you know exactly what is being served. Unfortunately, not every client will do this for you, but you can always ask or at least have the developers use the method to verify for themselves.
Remember that when using Dynamic Rendering, different user-agents are given different sets of code. Googlebot and other search engine bots should be receiving the prerendered code, and regular browsers should be receiving the code that’s rendered via client-side rendering. Developers can allow a unique user-agent to also have access to the prerendered code that Googlebot is getting. All you need to do then is set your user-agent to that unique user-agent so that you can pull in the code as well. Now you’ll have it direct from the server.
Conclusion
By understanding how to emulate a page, you’ll be able to diagnose issues that normally might stump you. Remember, the primary reason this is done is so that you can verify that prerendering is working and that Google is rendering content. Additionally, you want to make sure that any critical components of the page aren’t being locked behind Javascript functions. In our next guide on this topic we’ll show you a few examples of what to look for. Check it out.

